Text Phylogeny
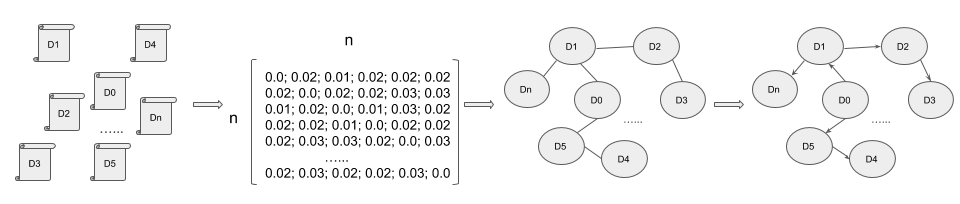
Given n texts, 1. An n * n dimensional dissimilarity matrix is calculated. 2. A minimum spanning tree algorithm is used to generate an undirected acyclic graph. 3. The root of the reconstructed phylogeny tree is determined, and directions are assigned to the edges of the graph.
The ease with which one can edit and redistribute digital documents on the Internet is one of modernity's great achievements, but it also leads to some vexing problems. With growing academic interest in the study of the evolution of digital writing on the one hand, and the rise of disinformation on the other, the problem of identifying the relationship between texts with similar content is becoming more important. Traditional vector space representations of texts have made progress in solving this problem when it is cast as a reconstruction task that organizes related texts into a tree expressing relationships --- this is dubbed text phylogeny in the information forensics literature. However, as new text representation methods have been successfully applied to many other text analysis problems, it is worth investigating if they too are useful in text phylogeny tree reconstruction. In this work, we explore the use of word embeddings as a text representation method, with the aim of trying to improve the accuracy of reconstructed phylogeny trees for real-world data and compare it with other widely used text representation methods. We evaluate the performance on established benchmarks for this task: a synthetic dataset and data collected from Wikipedia. We also apply our framework to a new dataset of fan fiction based on some famous fairy tales. Experimental results show that word embeddings are competitive with other feature sets for the published benchmarks, and are highly effective for creative writing.